
The Image Recognition Files: Part 1
Turns out the world's mightiest navies can't hide from the lowly port webcam

Today’s post includes:
More information than you’ll ever need to know about port webcams
Image recognition technology by way of Keras and TensorFlow
How I combined these two things to build the first iteration of a tool that uses image recognition to find warships sailing past public webcams
Need to convert geo coordinates into useful location information?

This week's edition is sponsored by OpenCage who operate a highly available, simple to use, worldwide, geocoding API based on open data. Try the API now on the OpenCage demo page.
By the way, if you’ve got a free 32 minutes, Ed and I had a nice conversation on the Geomob podcast about satellites and open data a few weeks ago, which you can find here.
Governments, journalists, shipping companies, open-source enthusiasts, and maritime watchers of all stripes spend a lot of time and effort figuring out where the world’s navies are. These folks use satellites, spies, listening devices, and I’m sure a host of other technology to determine where fleets are sailing.
What if there was a way to use a free, global, and always-on sensor network to pinpoint the voyages and port calls of naval vessels around the world?
Enter the humble port webcam. Local governments, companies, or port authorities set up webcams pointed at ports and publish the live-streamed footage online for the world to see.
Don’t believe me? Scroll through the last few hours of the San Diego port webcam and count how many US Navy ships you see going out to sea or coming back to port. I can almost guarantee that it’ll be…more than one. Indeed, folks like @WarshipCam have built a huge following by keeping tabs on these cameras and informing the general public of what ships they see on them.
At this point, you might be asking - why does it matter? Who the heck cares? Let’s discuss a recent example. As everyone knows by this point, Russia invaded Ukraine in late February. To supply its forces and conduct amphibious landings in Ukraine, Russia had to bring a few of its ships from the Baltic Fleet to the Black Sea.
Those ships had to pass through Denmark’s Great Belt to get to the North Sea, from which point they sailed through the English Channel, the Mediterranean Sea, the Bosporus Strait, and finally to the Black Sea and the shores of Ukraine. But first, they had to pass directly in front of the Storebaelt Bridge webcam, where WarshipCam and a band of other ship watchers were waiting:




Since I caught the machine learning bug a few weeks ago, a plan to detect these ships began to coalesce in my mind.
First, I would scrape @WarshipCam’s tweets (with their permission), then train an image recognition model on those images, and use the finalized model to predict whether new images contain warships or not.
Baking a Cake…a Data Cake
As always, if you want to skip the code, feel free to jump to the Predictions section below
The first step was to build a repository of images that I would train the model on1. WarshipCam graciously allowed me to scrape a few thousand of their most recent tweets to use as the “targets” in my code. In other words, the model would attempt to detect shapes in the new images that look like the shapes in WarshipCam’s tweets. By and large, these shapes look like warships.
But I couldn’t just use a single class (warships) to train the model. I also needed to show the model things that weren’t warships. To this end, I pulled a bunch of public images of civilian ships, beaches, the ocean, and marinas from stock photo sites (as well as the rare non-warship image that appeared in WarshipCam’s tweets).
I baked these ingredients into essentially a data cake - a combination of three delicious layers (warships, submarines, and not warships/submarines) that would fuel my model.
By the way, I ran all of this code in a Google Colab notebook using files stored in my Google Drive - it was really easy!
Anyway, using Keras, I imported the three layers into a notebook and split them into training and testing components.
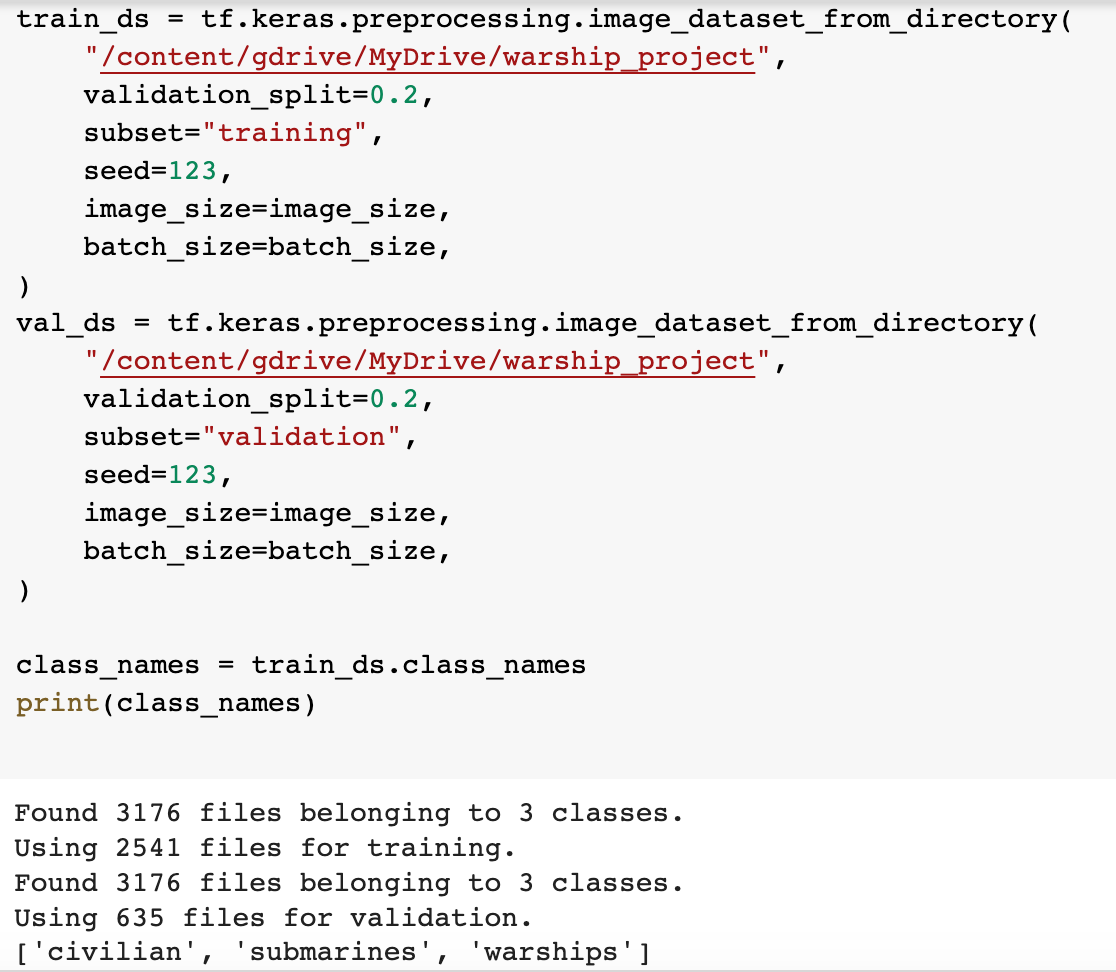
At this point, a note on the size of my data cake2 is in order. In the image above, you can see that it contains about 3,200 files overall. Ultimately, that’s not actually very much data. I initially tried to train a model from scratch on that data but try as I might, I couldn’t get the accuracy above 65-ish%. This is where two important features come in: augmentation and transfer learning.
Augmentation refers to introducing slight but believable variations in your training data to artificially expose the model to other aspects of the objects you’re trying to detect. For instance, if there was a picture of a ship in my training data, I may augment it to introduce a copy of that same exact picture but with the image rotated 10 degrees or flipped horizontally.

Transfer learning, on the other hand, is when you take a model that has already been trained on a different dataset and apply it to your training images. That way, your final model won’t have to learn as many features and can instead focus on the features that truly differentiate one class of your data from another.
If I were to train a model on my dataset from scratch, the model would have to learn, for example, the color of the sky and the sea in each image and determine if that was relevant in deciding if the image contained a warship or not. In my case, I chose to use the Xception model, which was already trained on a colossal dataset known as ImageNet. Since Xception (through ImageNet) has already been exposed to plenty of images of ships, it “knows” that images of ships contain blue sky and blue sea and it “knows” that blue sky and blue sea have little to no bearing on the shape of any ships in the image.
Modeling
Now comes the hard part: choosing, tweaking, and training a model. I used a really good tutorial the folks at Keras wrote about transfer learning models to actually construct my model.
By the way, when I talk about a “model” or the “Xception model”, I’m referring to a Convolutional Neural Network - the details of which could fill a dissertation. But for now, as this excellent Toward Data Science post explains:
A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning algorithm which can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other.
And that’s exactly what I’ll be doing with this model: taking an input image (ships), assigning importance (low to high) to objects in the image (guns, radars, cranes), and using those to differentiate one vessel (e.g. a cargo ship) from another (e.g. a submarine). But I recognize that pretty much no explanation will fully and concisely explain CNNs, so don’t worry if you don’t get the code - I barely do! If you like, you can read more about CNNs here.
Anyway, here’s the most important part of the code - where I introduce the pre-trained Xception model, tell it what size images to expect, and augment and scale the input data.

We can summarize this model in the table below. The training images “travel” from the input layers at top of this table, through the middle CNN and pooling layers, to the bottom layer, using the logic I defined in the code above. This process translates the characteristics of millions of training pixels into three condensed categories, i.e. the three types of vessels I’m trying to predict.

The summary shows that the pre-trained model has over 20 million parameters, which are essentially the things that are learned by the model (remember the blue sky/blue sea details above? Those are parameters!3)
Then I chose an optimizer, loss function, and the accuracy metrics to record. Afterwards came the actual most important part: crossing my fingers and slamming the “run code” button.

Not a bad run! As you can see, the loss decreases and the accuracy increases throughout the ten epochs, which is exactly what I wanted. Val_accuracy settled at around 90%, which indicates that the model predicted the correct ship type in about 90% of the images I set aside for testing. That’s a massive improvement over the 65% accuracy it attained before I introduced the pre-trained model.
Predictions
So after all that - data classes, transfer learning, and more - how would the model actually perform on new images it hadn’t seen before?
Let’s take a look at what the model guessed the type of vessel in the Storebaelt webcam image above is:

Sure, the model’s percent confidence in its prediction for this ship — a Russian Navy Ropucha-class landing ship — isn’t super high but it nonetheless accurately predicted the class of vessel in a grainy, far-away webcam shot, which I find pretty darn amazing.
The model works even better on clearer or closer shots of vessels in webcam images.

For instance, it is 84% confident in its (correct) guess that this Zumwalt-class destroyer is, in fact, a warship. But warships aren’t the only thing it guesses correctly! It also nailed the prediction for this webcam image of a Kilo-class submarine transiting the Bosporus Strait.

Also notice how the model doesn’t get confused by the presence of other objects in the shot, such as the buildings in the Zumwalt-class image or the tugboat in the Kilo-class image.
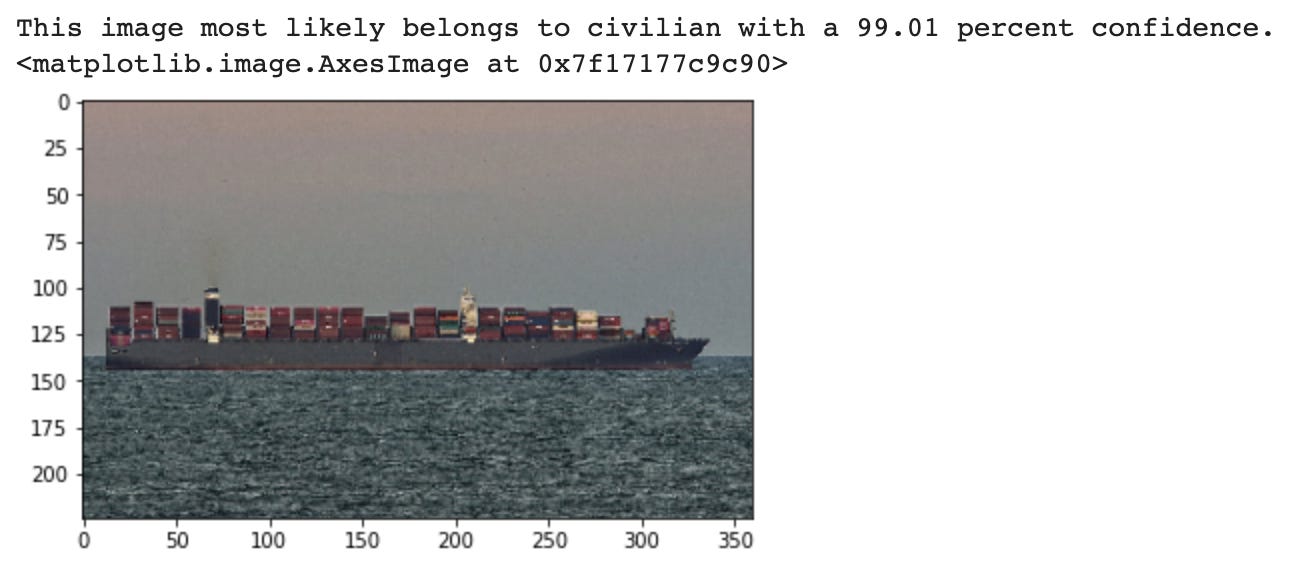
Lastly, let’s examine the counterfactual - what if the image shows civilian vessels? After all, the model isn’t much use if it can’t predict what’s not a warship or submarine. I loaded up a picture of a bunch of sailboats from the San Diego webcam…

…which it also predicted correctly! As it did with another picture of a merchant ship taken by maritime photographer John Morgan:
So what next? As I mentioned in the title of this blog post, this is just the first part of what I’m envisioning as a two-part image recognition series. I hope to use the second part to fine tune the model, boost its accuracy predictions, and start publishing some of the predictions. With that, I have two questions and a request for you, dear readers:
If/when I start publishing these images, where would you like to see them? On a Twitter account? A Google Drive/Dropbox-like folder? A website? Somewhere else?
Which port webcams should I draw from first? Feel free to peruse Windy.com’s webcams, look on WarshipCam’s Twitter account, or poke around your favorite coastal city to get a sense of which locations host port webcams.
Since the model learns from the images in my dataset, a great way to boost accuracy is to increase the number of images available. If you have (or know where to find) tons of free, easily accessible, and (ideally) pre-classified images of ships, don’t be a stranger!
If you’d like to reply to this post with your comments or suggestions, that’d be wonderful. If you just have a second, you can also vote on my Twitter polls:

Until next time, happy ship spotting!
As with most of my coding posts, I won’t show every single step here in the interest of preserving non-coding readers’ sanity. But if you want the full code, feel free to reach out!
Am I beating this metaphor to death? Yes.
Is the application available for download to test?